

Through “bedtime stories” written by other LLMs, Phi-3 gained knowledge.
Microsoft introduced the first of three compact versions it intends to deliver, the Phi-3 Mini, the company’s latest lightweight AI model.
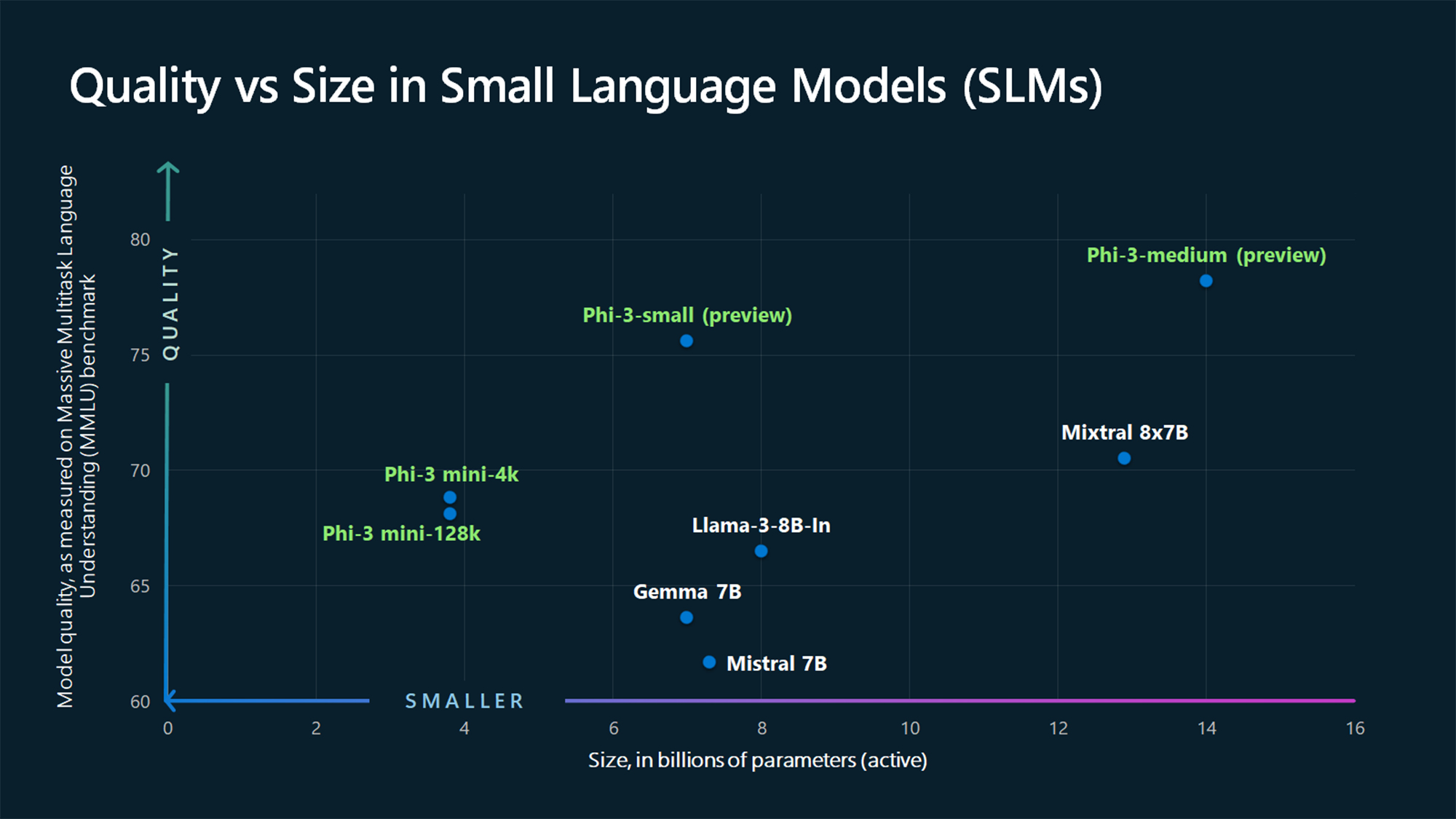
Comparatively speaking to large language models such as GPT-4, Phi-3 Mini has a smaller training set and measures 3.8 billion parameters. Hugging Face, Ollama, and Azure are currently selling it. Microsoft intends to make available Phi-3 Medium (14B parameters) and Phi-3 Small (7B parameters). A model’s parameter count is the number of complex instructions it can comprehend.
In December, the business unveiled Phi-2, which outperformed larger models, notably Llama 2. According to Microsoft, Phi-3 outperforms the previous iteration and can yield results that are comparable to those of a model ten times larger.
Phi-3 Mini is just as powerful as LLMs like GPT-3.5, but in a smaller size factor, according to Eric Boyd, executive vice chairman of Microsoft Azure Intelligence Framework, who spoke with The Verge.
Smaller AI models operate more affordably and deliver superior performance on mobile devices such as laptops and phones than their larger versions. Earlier in the year, The Information revealed that Microsoft was assembling a team dedicated to creating AI models that are more lightweight. In addition to Phi, the business has developed a math-focused model called Orca-Math.
Rivals of Microsoft also have tiny artificial intelligence models; most of these focus on more straightforward tasks like helping with coding or summarizing documents. Gemma 2B and 7B from Google are useful for language-related tasks and basic chatbots. Claude 3 Haiku from Anthropic can swiftly explain complex research papers with graphs, while Llama 3 8B, which Meta recently released, can be used for specific chatbots and coding help.
According to Boyd, developers used a “curriculum” to train Phi-3. Their inspiration came from the way kids picked up knowledge from bedtime stories, simpler-word novels, and language structures that addressed more complex subjects.
Boyd explains, “We selected an array of over three thousand terms and hired an LLM to produce ‘children’s books’ to teach Phi because there aren’t enough children’s books out there.”
He continued saying that Phi-3 only built on what earlier iterations had discovered. Phi-3 is superior at both coding and reasoning, whereas Phi–1 concentrates on programming, and Phi-2 starts to learn to reason. A GPT-4 or equivalent LLM can outperform the Phi-3 series of algorithms in terms of breadth, even if the former can learn more general information than the latter. An LLM developed on the whole internet will yield very different answers than smaller versions like Phi-3.
According to Boyd, businesses frequently discover that smaller models, such as Phi-3, perform better for their applications because many companies already have very modest internal data sets. Furthermore, these models are frequently significantly more economical because they require less processing power.


{kind=link}