

During a recent GTC meeting, Nvidia introduced Nvidia NIM, an innovative software system that makes it easier to integrate pre-trained and customized artificially intelligent models into production settings. By integrating a particular model with an optimal inferencing engine and placing this inside a container, which makes it accessible as a microservice, NIM utilizes the software development effort Nvidia has accomplished in interpreting and optimizing algorithms in order to make it merely available.
Nvidia claims that normally, it would require developers weeks, or perhaps months, to ship comparable containers—and that’s assuming the business even has any artificial intelligence experts on staff. With NIM, Nvidia is making it plain that its goal is to build an ecosystem of Intelligence-ready containers, with its hardware serving as the base and these carefully chosen microservices as the main software layer, enabling businesses looking to accelerate their AI roadmaps.

As of right now, NIM supports open structures from Google, Hugging Face, Meta, Microsoft, Mistral artificial intelligence, Stable AI, A121, Adept, Cohere, Getty Images, and Shutterstock in addition to models from NVIDIA. Nvidia is already in collaboration with Amazon, Google, and Microsoft in order to create these NIM components accessible via SageMaker, Kubernetes Engine, and Azure AI, respectivel. Additionally, Deepset, LangChain, and LlamaIndex frameworks are also going to incorporate them.
Speaking at a media briefing before today’s announcements, Manuvir Das, the manager of business computing at Nvidia, stated, “We feel the fact that Nvidia GPU is the ideal spot to operate inference of such models on, and we believe that NVIDIA NIM is the most effective software package, the ideal execution, for programmers to establish on the high point of in order to are able to concentrate on the enterprise applications— as well as equitable enable Nvidia perform the job to generate these algorithms for them in the most effective enterprise-grade style so that they am able to perform every aspect of their work.”
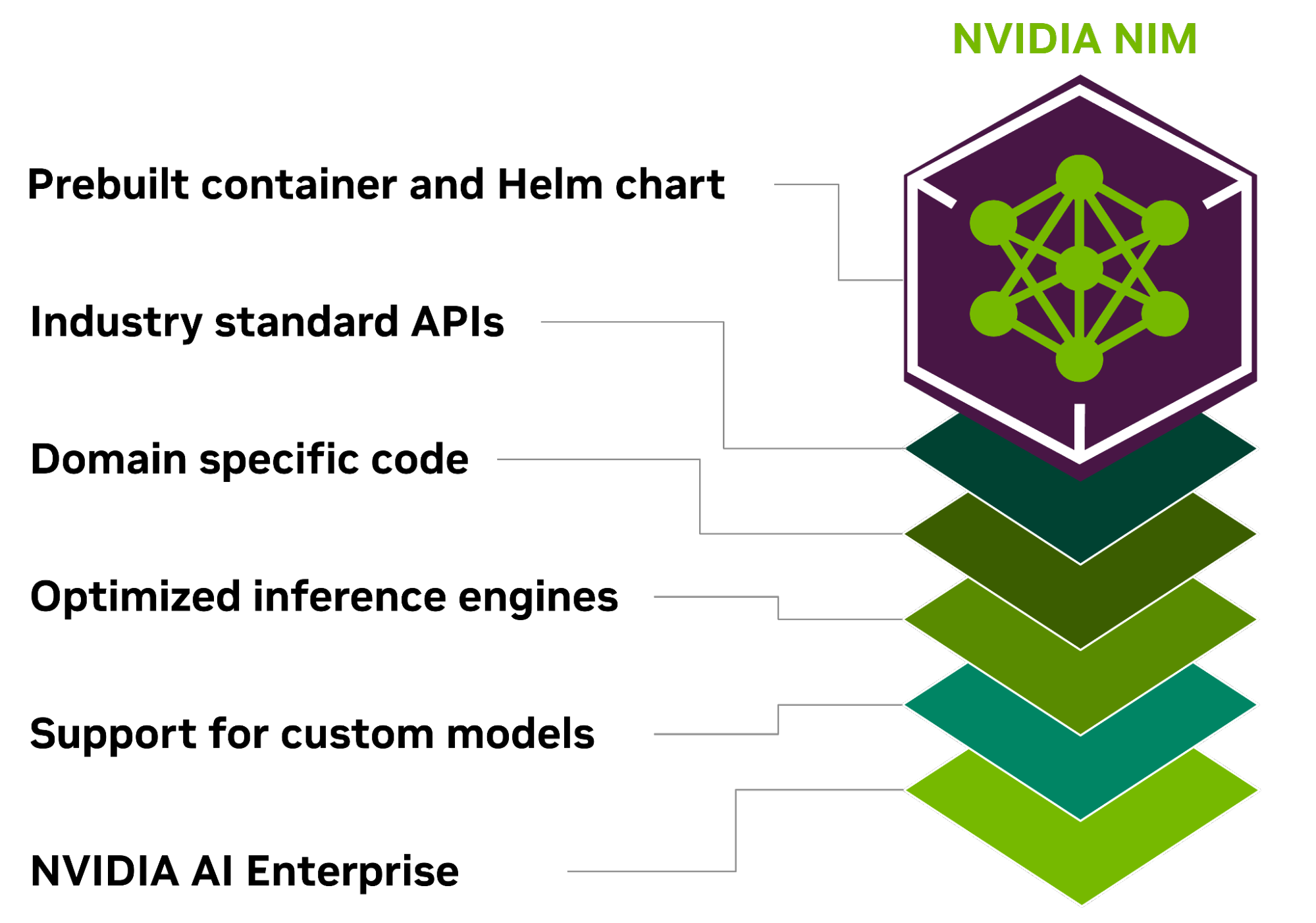
Nvidia will make use of TensorRT, TensorRT-LLM, and the Triton Inference Server as its inference engine. The Earth-2 model, which simulates weather and climate; cuOpt, which optimizes routing; and Riva, which allows customization for speaking and translation models, are a few of the Nvidia microservices made available by NIM.
The business intends to introduce more features in the future. One such feature is the availability of the Nvidia RAG LLM operator as an NIM, which should make it much simpler to create generative chatbots with artificial intelligence that can bring in unique input.
Without a couple of updates from partners and customers, this will not be a developer convention. Companies like Box, Cloudera, Cohesity, Datastax, Dropbox, and NetApp are among NIM’s current clients.
According to Jensen Huang, the proprietor and chief executive officer of NVIDIA, existing business systems contain a wealth of information that may be turned into generative artificial intelligence copilots. These containerized Intelligence microservices, developed in collaboration with companies affiliated with our ecosystem, are the cornerstones that enable businesses across all sectors to become AI firms.


{kind=link}