

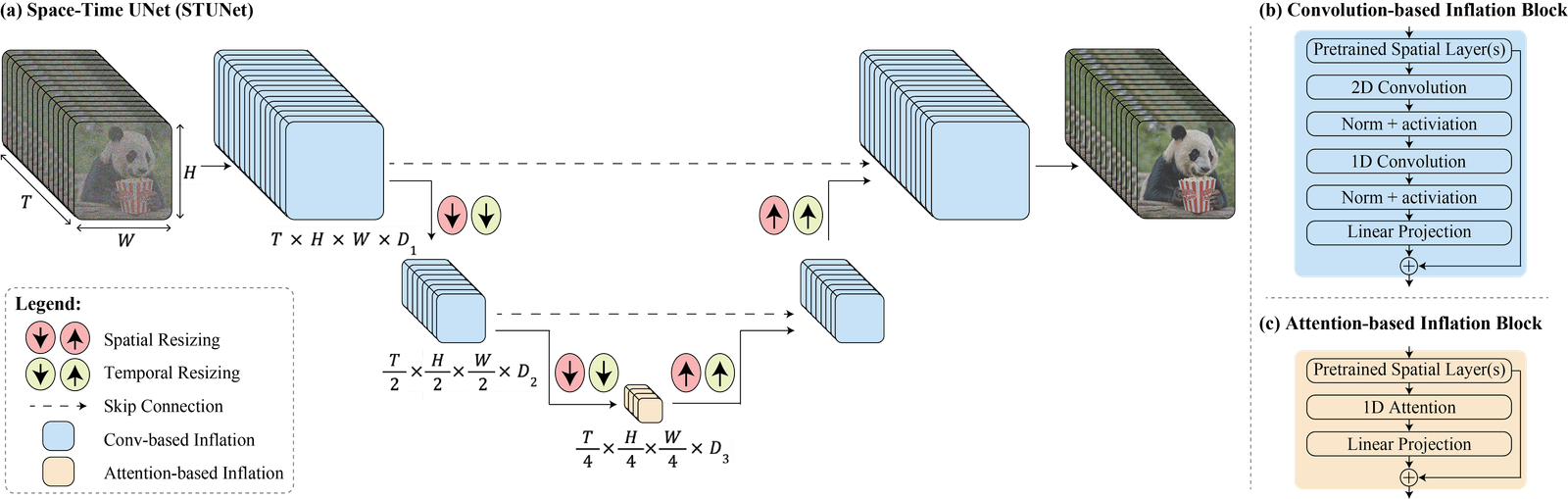
Lumiere, Google’s latest artificial intelligence model for creating videos, makes use of a groundbreaking diffusion model known as Space-Time-U-Net, or STUNet, to determine the location of objects in a movie (space) and their motion and change over time (time). Instead of piecing together individual still images, Lumiere can now make the whole video in a single pass, according to Ars Technica.
Here is a great video on Google Lumiere AI:
Lumiere’s ability to make short, realistic video snippets from a prompt is demonstrated by these five-second clips. Using the prompt as a starting point, Lumiere creates a base frame. Next, it creates more frames that blend into each other, giving the impression of smooth motion, by using its STUNet framework to start estimating where items inside that frame would travel. In comparison to Stable Video Diffusion’s 25 frames, Lumiere produces 80 frames.
Google Research has unveiled Lumiere, a groundbreaking text-to-video diffusion model designed to create highly realistic videos based on text or image prompts. #GoogleLumiere https://t.co/ISmpZFec4t
— Signpost News (@signpost_news) January 26, 2024
Although if you prefer writing reports to watch videos, the accompanying sizzle reel and pre-print scientific study from Google demonstrate that artificial intelligence video editing and generating technologies have rapidly progressed from strange valley to nearly realistic in the span of a few years. Additionally, it solidifies Google’s technology in a market where rivals such as Stable Video Diffusion, Meta’s Emu, and Runway already exist. Launched in March of last year, Runway Gen-2 began providing videos with a more realistic appearance. Runway became one of the very first mass-market text-to-video services. But, runway videos aren’t great at showing actions.
Lumiere:
Google kindly provided the Lumiere site with clips and questions, so one could compare them using Runway or other apps.
If you examine the skin texture or the atmospheric lighting in particular, you can notice that a few of the clips seem a little too staged. However, see the turtle! When submerged, it mimics a turtle’s natural swimming motions. That thing resembles a genuine turtle! An experienced video editor received the Lumiere intro clip and reviewed it. She did note that “you can tell it’s not entirely real,” but she found it remarkable that she would have assumed it was computer-generated imagery (CGI) if I hadn’t informed her it was artificial intelligence. She also stated, “It’s going to take my job, isn’t it?”
In contrast to other models, which piece together videos by generating crucial frames at points when the movement has already occurred (like flip book drawings), STUNet allows Lumiere to concentrate on the movement by determining the appropriate location for the created information at any point in the video.
Though it has been steadily releasing more sophisticated AI models and leaning toward a more multimodal focus, Google has not been a major participant in the text-to-video area. Bard will be able to generate images in the future thanks to the Gemini LLM. Although Lumiere isn’t ready for testing just yet, it demonstrates that Google can build an AI video platform as par with, and maybe even better than, readily accessible AI video generators such as Pika and Runway. To refresh your memory, this was Google’s AI video state two years ago.
:no_upscale():format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24086506/imagen_multi_clip_gif.gif)
Along with text-to-video generation, Lumiere will additionally support image-to-video generation, styled generation (which lets users create videos in a specific manner), cinematography (which animate only a portion of a video), and inpainting (which masks out a region of the video to modify the color or pattern), among other features.
“[W]e believe that it is crucial to develop and apply tools for detecting biases and malicious use cases to ensure a safe and fair use,” Google stated in its Lumiere paper, “there is a risk of misuse for creating fake or harmful content with our technology.” However, no details on how to accomplish this were provided by the authors of the paper.


{kind=link}